Titanic
타이타닉 대회
타이타닉호에 탑승한 승객에 대한 다양한 정보가 포함된 데이터 세트를 제공받고, 그 정보를 사용하여 사람들이 생존했는지 여부를 예측할 수 있는지 살펴봅니다.
Kaggle 대회는 두 개의 훈련 세트와 테스트 세트가 있습니다.
훈련 세트는 우리 모델을 훈련하는 데 사용할 수 있는 데이터를 포함합니다. 다양한 기술적 데이터를 포함하는 여러 개의 특성 열이 있으며, 이 경우에는 생존(Survived) 에 대해 예측하려는 대상 값 열도 있습니다
테스트 세트는 모든 동일한 특성 열을 포함하지만, 예측 대상 값 열이 빠져있습니다. 또한 테스트 세트는 일반적으로 훈련 세트보다 적은 관측치(행)를 가지고 있습니다.
훈련 세트와 테스트 세트 두 파일은 test.csv와 train.csv로 이름이 지정됩니다.
먼저 훈련 세트와 테스트 세트를 불러 오고, 그 크기를 살펴봅시다.
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
train = pd.read_csv('/kaggle/input/titanic/train.csv')
test = pd.read_csv('/kaggle/input/titanic/test.csv')
print("Dimensions of train: {}".format(train.shape))
print("Dimensions of test: {}".format(test.shape))
Dimensions of train: (891, 12)
Dimensions of test: (418, 11)
데이터 탐색
데이터의 각 특성은 다음과 같습니다:
- PassengerId: 각 승객의 고유 식별자
- Survived: 목표값으로, 0은 승객이 사망한 것을 의미하고, 1은 생존한 것을 의미
- Pclass: 승객 등급
- Name, Sex, Age: 이름, 성, 나이
- SibSp: 승객이 타이타닉 호에 탑승한 동생/배우자 수
- Parch: 승객이 타이타닉 호에 탑승한 부모/자녀 수
- Ticket: 티켓 ID
-
Fare: 지불한 가격 (파운드)
- Cabin: 승객의 객실 번호
- Embarked: 승객이 타이타닉 호에 탑승한 장소
훈련 세트의 상위 5개열 추출합니다.
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
이 경우, 타이타닉 호 재난을 이해하고 생존 결과에 영향을 미칠 수 있는 변수를 구체적으로 파악하는 것이 중요합니다.
타이타닉 영화를 본 사람이라면 여성과 아이들이 구명보트를 선호 받았으며 (실제로도 그렇게 이루어졌습니다), 승객들 간의 큰 계급 격차를 기억할 것입니다.
이는 나이, 성별 및 승객 등급(PClass)이 생존 예측에 좋은 지표일 수 있다는 것을 나타냅니다. 이를 시각화하면서 성별과 승객 등급(PClass)을 탐색하여 시작하겠습니다.
먼저 시각화를 위한 패키지들을 추가하고, 가장 중요한 생사여부에 대한 정보를 시각적으로 표시하도록 하겠습니다. 훈련데이터가 들어간 데이터 프레임 train_df에서 Survived 키를 통해 생사여부의 정보를 가져올 수 있습니다.
import seaborn as sns
import matplotlib.pyplot as plt
f, ax=plt.subplots(1, 2, figsize=(18,8))
train['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot(x = 'Survived',data=train,ax=ax[1]) # "Survived가 x축인지 y 인지 알려주어야"
ax[1].set_title('Survived')
plt.show()
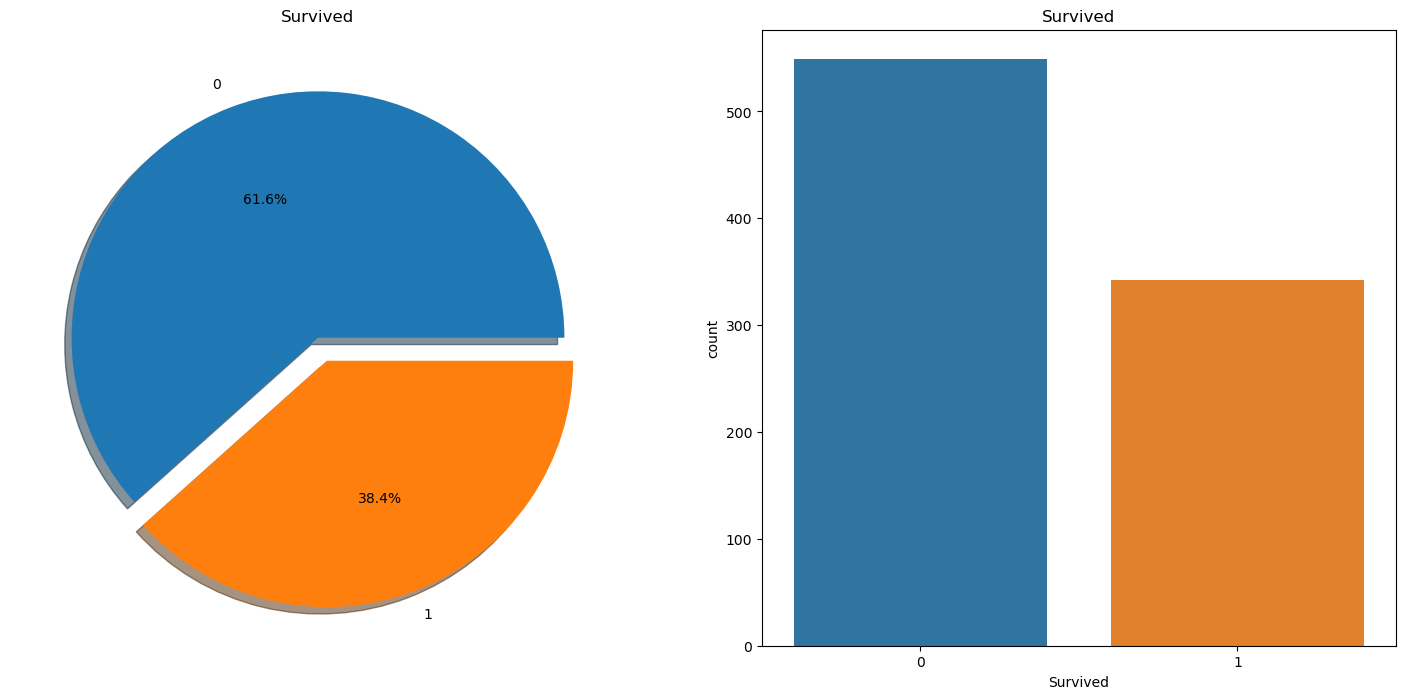
0은 사망, 1은 생존을 의미합니다. 즉 탑승객의 60% 이상이 사망했다는 결론을 얻을 수 있습니다.
이번에는 남녀별 생존 비율을 확인해 보도록 하겠습니다.
다음 코드는 train_df[‘Survived’]의 데이터에서 성별을 기준으로 필터링된 값을 가지고 비교합니다.
f,ax=plt.subplots(1,2,figsize=(18,8))
train['Survived'][train['Sex']=='male'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
train['Survived'][train['Sex']=='female'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[1],shadow=True)
ax[0].set_title('Survived (male)')
ax[1].set_title('Survived (female)')
plt.show()
sex_pivot = train.pivot_table(index="Sex",values="Survived")
sex_pivot.plot.bar()
plt.show()
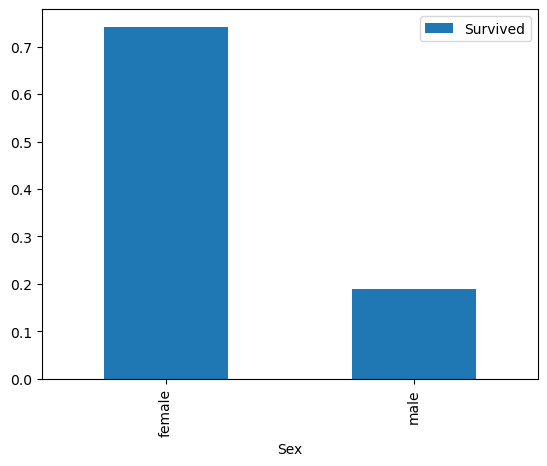
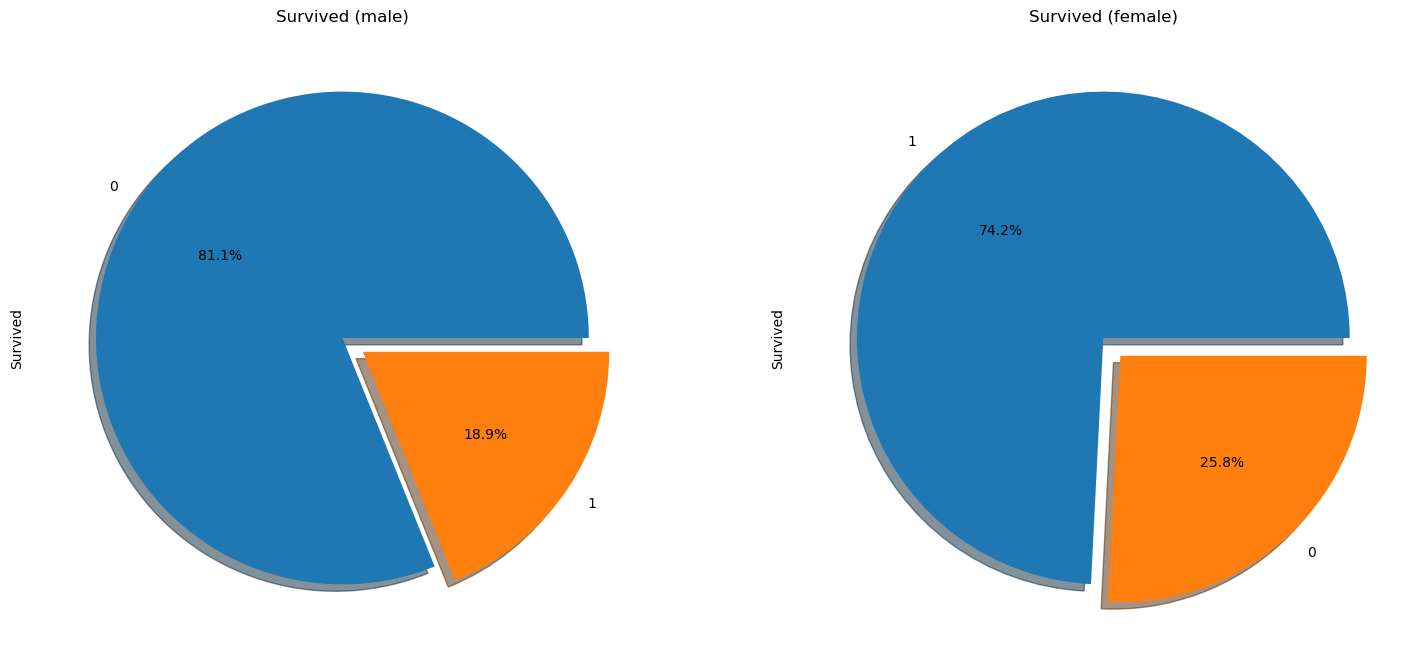
생존한 경우 Survived 열에는 승객이 생존하지 못한 경우 0, 생존한 경우 1이 포함되어 있으므로, 성별에 따라 데이터를 분할하고 이 열의 평균을 계산할 수 있습니다.
따라서 위 그래프에서 남자의 사망률은 80% 이상인 반면 여자의 사망률은 약 25%정도임을 확인할 수 있습니다
Pclass 열에 대해서도 같은 작업을 수행해 보겠습니다.
class_pivot = train.pivot_table(index="Pclass",values="Survived")
class_pivot.plot.bar()
plt.show()
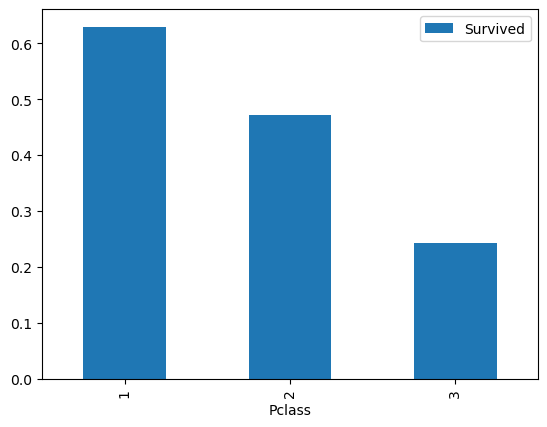
이번에는 그래프가 아닌 pandas의 자체 table 기능을 사용해서 객실 등급 데이터인 Pclass를 탐색해 보도록 하겠습니다.
pd.crosstab([train['Sex'],train['Survived']],train['Pclass'],margins=True).style.background_gradient(cmap='summer_r')
| Pclass | 1 | 2 | 3 | All | |
|---|---|---|---|---|---|
| Sex | Survived | ||||
| female | 0 | 3 | 6 | 72 | 81 |
| 1 | 91 | 70 | 72 | 233 | |
| male | 0 | 77 | 91 | 300 | 468 |
| 1 | 45 | 17 | 47 | 109 | |
| All | 216 | 184 | 491 | 891 |
여기에서 우리가 확인할 수 있는 정보들은 다음과 같습니다.
- 1등 객실 여성의 생존률은 91/94 = 97%, 3등 객실 여성의 생존률은 50%
- 남성의 경우에 1등 객실 생존률은 37%, 3등 객실은 13%
즉 낮은 등급의 객실의 사망률이 높았다는 것으로, 좋은 자리값을 했다는 것을 볼 수 있습니다.
나이 열(변수)을 탐색하고 변환하기
Sex와 PClass 열은 범주형(categorical) 특징이라고 부릅니다. 즉, 값은 몇 가지 분리된 옵션을 나타냅니다(예: 승객이 남성인지 여성인지 여부).
train["Age"].describe()
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
Age 열은 0.42에서 80.0까지의 숫자를 포함하고 있습니다. 또 다른 주목할 점은 이 열에는 714개의 값이 있으며, 이전 수업에서 발견한 학습 데이터 세트의 814개의 행보다 적은 것을 알 수 있습니다. 이는 결측값이 일부 존재한다는 것을 나타냅니다.
우리는 살아남은 사람들과 나이에 따라 다른 연령대의 사망자들을 시각적으로 비교하기 위해 두 개의 히스토그램을 생성할 수 있습니다.
survived = train[train["Survived"] == 1]
died = train[train["Survived"] == 0]
survived["Age"].plot.hist(alpha=0.5,color='red',bins=50)
died["Age"].plot.hist(alpha=0.5,color='blue',bins=50)
plt.legend(['Survived','Died'])
plt.show()
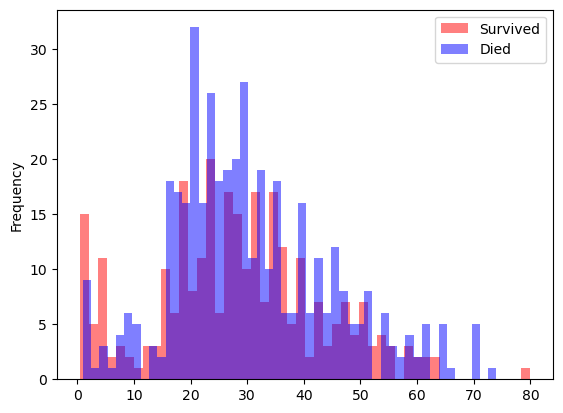
간단하게 판단할게 아니지만, 일부 연령 범위에서는 더 많은 승객들이 생존한 것으로 나타납니다. 여기서 빨간 막대가 파란 막대보다 높은 경우입니다.
이를 머신러닝 모델에 유용하게 만들기 위해, pandas.cut() 함수를 사용해 연속적인 특성을 범주형 특성으로 분할하여 구간으로 나눌 수 있습니다.
위에서 나타난 바와 같이 Age 열에는 결측값이 포함되어 있어 이를 처리해줘야합니다. 또한, 수정한 내용은 테스트 데이터에도 적용해야합니다.
- andas.fillna() 메서드를 사용하여 모든 결측값을 -0.5로 채
- Age 열을 6개 구간으로 나눔
- 결측값, -1에서 0 사이
- 유아, 0에서 5 사이
- 어린이, 5에서 12 사이
- 청소년, 12에서 18 사이
- 젊은 성인, 18에서 35 사이
- 성인, 35에서 60 사이
- 노인, 60에서 100 사이
아래 그림은 이 함수가 데이터를 어떻게 변환하는지를 보여줍니다.
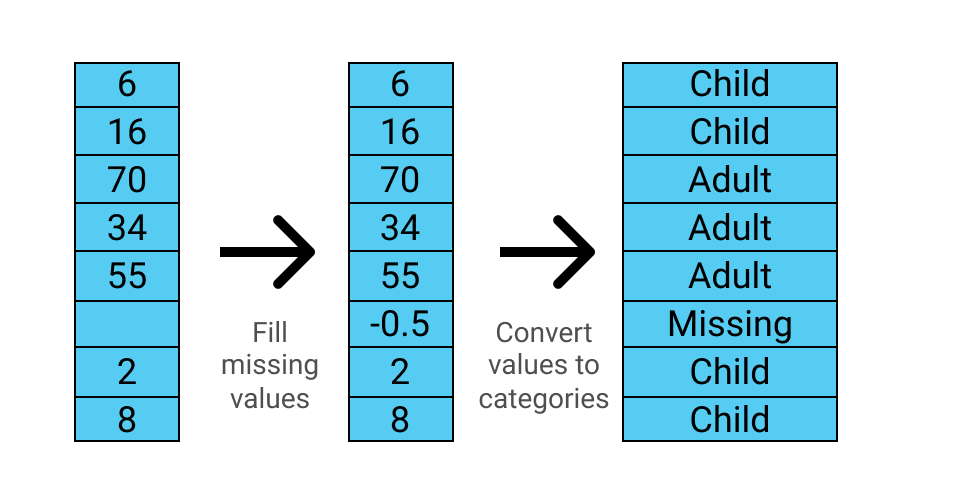
아래 코드는 process_age() 함수를 사용하여 train과 test 데이터프레임의 Age 컬럼을 범주형으로 변환합니다. 이후 변환된 데이터를 이용하여 pivot table을 만들고 시각화합니다.
여기서 process_age() 함수는 입력받은 데이터프레임(df)의 “Age” 열을 가공하여 “Age_categories” 열을 추가하는 기능을 합니다.
def process_age(df,cut_points,label_names):
df["Age"] = df["Age"].fillna(-0.5)
df["Age_categories"] = pd.cut(df["Age"],cut_points,labels=label_names)
return df
cut_points = [-1,0,5,12,18,35,60,100]
label_names = ["Missing","Infant","Child","Teenager","Young Adult","Adult","Senior"]
train = process_age(train,cut_points,label_names)
test = process_age(test,cut_points,label_names)
pivot = train.pivot_table(index="Age_categories",values='Survived')
pivot.plot.bar()
plt.show()
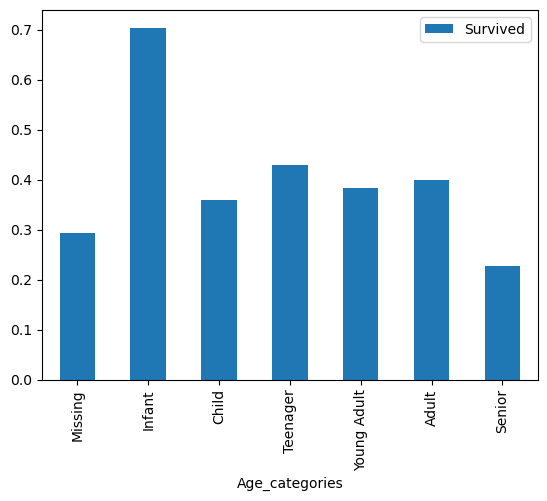
머신 러닝 위해 데이터 준비하기
우리는 다음 세 가지 열이 생존을 예측하는 데 유용할 수 있다고 식별했습니다.
- 성별
- Pclass
- 나이, 또는 더 구체적으로 새롭게 만든 Age_categories
모델을 구축하기 전에 이러한 열을 기계 학습에 맞게 준비해야합니다. 대부분의 머신러 알고리즘은 텍스트 레이블을 이해하지 못하므로 값을 숫자로 변환해야합니다.
또한 관계가 없는 경우 숫자 관계를 시사하지 않도록 주의해야합니다. 데이터 사전은 Pclass 열의 값이 1, 2 및 3임을 알려줍니다.
train["Pclass"].value_counts()
3 491
1 216
2 184
Name: Pclass, dtype: int64
각 승객 클래스에 대한 순서관계가 있긴 하지만, 숫자 1, 2, 3 간의 관계와 동일하지 않습니다.
이 관계를 제거하기 위해 Pclass의 각 고유 값에 대해 더미 열을 만들 수 있습니다:
pandas.get_dummies() 함수를 사용하여 Pclass에 대한 더미 열을 생성할 수 있습니다. 이 함수는 위에서 보여준 열들을 생성해줍니다.
Pclass 열에 대한 더미 열을 만들고 원래 데이터 프레임에 다시 추가하는 함수를 만듭니다. 그리고 그 함수를 Pclass, Sex, Age_categories 열에 대해 train 및 test 데이터 프레임에 적용합니다.
def create_dummies(df,column_name):
dummies = pd.get_dummies(df[column_name],prefix=column_name)
df = pd.concat([df,dummies],axis=1)
return df
for column in ["Pclass","Sex","Age_categories"]:
train = create_dummies(train,column)
test = create_dummies(test,column)
첫번째 머신러닝 모델 만들기
데이터가 준비되었으니 첫번째 모델을 훈련시킬 준비가 되었습니다. 첫번째 모델로는 Logistic Regression을 사용합니다. 이는 분류 작업을 할 때 보통 처음으로 사용되는 모델입니다.
이를 위해 머신러닝을 수행하는 데 많은 도구를 제공하는 scikit-learn 라이브러리를 사용합니다. scikit-learn 워크플로우는 주로 4단계로 구성됩니다.
- 사용하고자 하는 머신러닝 모델을 생성합니다.
- 모델을 훈련 데이터에 맞춥니다.
- 모델을 사용하여 예측합니다.
- 예측 결과의 정확도를 평가합니다.
scikit-learn에서 모델은 모두 별도의 클래스로 구현되며, 첫번째 단계는 생성할 클래스를 식별하는 것입니다. 이번에는 LogisticRegression 클래스를 사용하고자 합니다.
클래스를 import하고 LogisticRegression 객체를 생성합니다.
마지막으로 LogisticRegression.fit() 메서드를 사용하여 모델을 학습합니다. .fit() 메서드는 두 개의 인자 X와 y를 받습니다. X는 모델을 학습시킬 feature의 2차원 배열(데이터프레임과 유사한 형태)이어야 하며, y는 예측하고자 하는 target(또는 예측하고자 하는 열)의 1차원 배열(시리즈와 유사한 형태)이어야 합니다.
이제 create_dummies() 함수로 생성된 모든 열을 사용하여 모델을 훈련해보겠습니다
from sklearn.linear_model import LogisticRegression
columns = ['Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex_female', 'Sex_male',
'Age_categories_Missing','Age_categories_Infant',
'Age_categories_Child', 'Age_categories_Teenager',
'Age_categories_Young Adult', 'Age_categories_Adult',
'Age_categories_Senior']
lr = LogisticRegression()
lr.fit(train[columns], train["Survived"])
LogisticRegression()
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
LogisticRegression(multi_class='ovr', n_jobs=1, solver='liblinear')
머신 러닝 모델을 학습했습니다. 이제 모델의 정확도를 파악하기 위해 몇 가지 예측을 해야합니다.
예측에 사용할 수 있는 테스트 데이터프레임이 있습지만 이 데이터 프레임에는 생존 컬럼이 없기 때문에 정확도를 파악하려면 Kaggle에 제출해야합니다.
학습 데이터프레임에 맞추고 예측할 수도 있지만 이렇게하면 모델이 오버핏될 가능성이 높습니다. 즉, 학습한 데이터와 동일한 데이터에서 테스트하기 때문에 잘 수행되지만 새로운데이터에서 훨씬 안좋은 결과를 보여주는 경우가 많습니다.
학습 데이터프레임을 두 개로 나눌 수 있습니다.
- 모델을 학습하는 데 사용할 부분 (보통 관측치의 80 %)
- 예측을 수행하고 모델을 테스트하는 데 사용할 부분 (보통 관측치의 20 %)
머신 러닝에서 이러한 두 부분을 각각 훈련 및 테스트라고 부릅니다. 하지만 우리는 Kaggle에 제출할 예측을 위해 사용할 테스트 데이터프레임과의 혼란을 방지하기 위해 여기서부터는 이러한 유형의 최종 예측에 사용되는 데이터를 홀드아웃 데이터라고 부르도록 합시다.
scikit-learn 라이브러리에는 데이터를 나누기 위해 사용할 수있는 유용한 model_selection.train_test_split() 함수가 있습니다. train_test_split() 함수는 모든 훈련 및 테스트에 사용할 데이터를 포함하는 X와 y 두 매개 변수를 받고 train_X, train_y, test_X, test_y 네 가지 개체를 반환합니다.
train_test_split() 함수에서는 test_size와 random_state와 같은 추가적인 매개변수를 사용합니다.
holdout = test # from now on we will refer to this
# dataframe as the holdout data
from sklearn.model_selection import train_test_split
all_X = train[columns]
all_y = train['Survived']
train_X, test_X, train_y, test_y = train_test_split(
all_X, all_y, test_size=0.20,random_state=0)
예측 및 정확도 측정
이제 우리는 데이터를 훈련 세트와 테스트 세트로 나누었으므로, 훈련 세트에서 모델을 다시 피팅하고 그 모델을 사용하여 테스트 세트에서 예측을 할 수 있습니다.
모델을 피팅한 후에는 LogisticRegression.predict() 메소드를 사용하여 예측을 할 수 있습니다.
predict() 메소드는 하나의 매개변수 X를 사용하며, 이는 우리가 예측하려는 관측치의 특징들로 이루어진 2차원 배열입니다. X는 우리가 모델을 피팅할 때 사용한 배열과 정확히 동일한 특징을 가져야 합니다. 이 메소드는 예측의 1차원 배열을 반환합니다.
다음은 Kaggle의 Titanic 대회의 평가 섹션 “올바르게 예측된 승객의 비율”로 계산된 점수를 사용하여 정확도를 계산합니다.
첫 번째 정확도 점수를 계산해봅시다.
from sklearn.metrics import accuracy_score
lr = LogisticRegression()
lr.fit(train_X, train_y)
predictions = lr.predict(test_X)
accuracy = accuracy_score(test_y, predictions)
print(accuracy)
0.8100558659217877
교차 검증(Cross validation)을 사용하여 더 정확한 오류 측정
모델의 정확도 점수는 20%의 테스트 세트에 대해 81.0%입니다. 이 데이터셋이 꽤 작기 때문에 모델이 과적합되어 있어서 전혀 보지 못한 데이터에서는 잘 동작하지 않을 가능성이 높습니다. 때문에 교차 검증 기술을 사용하여 데이터를 다른 분할로 학습 및 테스트하고 정확도 점수를 평균화할 수 있습니다.
가장 일반적인 교차 검증 방법은 k-fold 교차 검증입니다. Fold 는 모델을 학습하는 각 반복을 의미하고, k는 폴드의 수를 의미합니다.
ross_val_score() 함수는 각 fold의 정확도 점수들을 numpy ndarray 형태로 반환합니다. cross_val_score() 함수는 다양한 교차 검증 기술과 평가 지표를 사용할 수 있지만, 기본적으로는 k-fold 검증과 정확도 점수를 사용합니다.
다음 코드는 cross_val_score() 함수를 사용하여 교차 검증을 수행하고, 만들어진 점수들의 평균을 계산합니다.
from sklearn.model_selection import cross_val_score
lr = LogisticRegression()
scores = cross_val_score(lr, all_X, all_y, cv=10)
scores.sort()
accuracy = scores.mean()
print(scores)
print(accuracy)
[0.76404494 0.76404494 0.76404494 0.78651685 0.8 0.80898876
0.80898876 0.82022472 0.83146067 0.87640449]
0.8024719101123596
새로운 데이터에 대한 예측 생성
우리가 수행한 k-fold 검증 결과, 76.4% 부터 87.6% 까지 범위가 있는걸로 보아, 정확도 숫자가 각각의 폴드마다 다르다는 것을 볼 수 있습니다.
우리의 평균 정확도 점수는 80.2% 였으며, 이는 간단한 train/test 분할에서 얻은 81.0% 와 크게 차이 나지 않습니다. 그러나 항상 모델에서 얻는 오류 메트릭이 정확한지 확인하기 위해 교차 검증을 사용해야 합니다.
lr = LogisticRegression()
lr.fit(all_X,all_y)
holdout_predictions = lr.predict(holdout[columns])
서브레슨 파일 생성하기
Titanic 대회 평가 페이지에서는 다음과 같이 sublesson 파일에 대한 요구 사항을 명시하고 있습니다:
“PassengerId“와 “Survived” 두 개의 열만 포함하며, 헤더 행을 포함해 정확히 418개의 항목이 있어야 합니다. “PassengerId“는 어떤 순서로든 정렬할 수 있습니다.
파일은 정확히 2개의 열을 가져야 합니다:
- PassengerId (어떤 순서로든 정렬됨)
- Survived (1은 생존, 0은 사망을 나타냄)
앞서 본 holdout_predictions와 holdout dataframe의 PassengerId 열을 포함하는 새로운 데이터프레임을 만들어야 합니다. 이 두 데이터는 원래의 순서를 유지하므로 데이터를 일치시키는 데 걱정할 필요가 없습니다.
이를 위해, pandas.DataFrame() 함수에 딕셔너리를 전달할 수 있습니다.
holdout_ids = holdout["PassengerId"]
sublesson_df = {"PassengerId": holdout_ids,
"Survived": holdout_predictions}
sublesson = pd.DataFrame(sublesson_df)
마지막으로, DataFrame.to_csv() 메소드를 사용하여 데이터프레임을 CSV 파일로 저장합니다. index 매개변수가 False로 설정되어 있는지 확인해야합니다. 그렇지 않으면 CSV에 추가 열이 추가됩니다.
sublesson.to_csv("sublesson.csv",index=False)
캐글 타이타닉 경진대회 등수 사진
